Don't Wrangle, Guess
One of the biggest costs in analytics is data wrangling: Getting your messy, mis-labeled, disorganized data together so you can actually ask your questions. All data wrangling tools force you to do all this work upfront, before you actually know what you even want to do with the data. Mimir lets you at your data sooner by tracking your cleaning todos. Ask first, clean later, with Mimir.
Mimir is about getting you to your analysis as fast as possible. It lets you harness the raw power of SQL, StackOverflow's second-most popular language for 4 years running. Mimir then adds a ton of powerful SQL extensions designed to dealing with messy data easier:
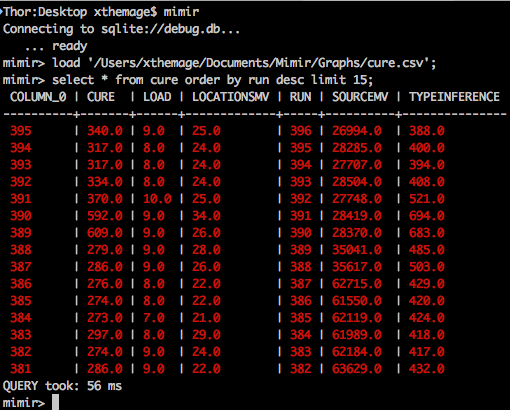
LOAD
Stop messing with data import and relational schema design. The versatile LOAD command allows you to quickly transform documents into relational tables without the muss and fuss of upfront schema design or defining complex transformation operators.
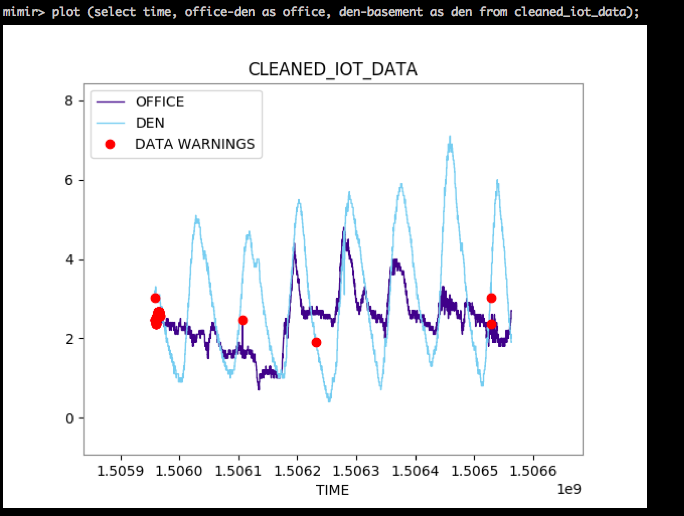
PLOT
Stop writing messy scripts to visualize your data. The PLOT command lets you take SQL queries and see them directly – notebook style, PDF/PNG, or Javascript, take your pick. Mimir even keeps track of unknowns in your data.
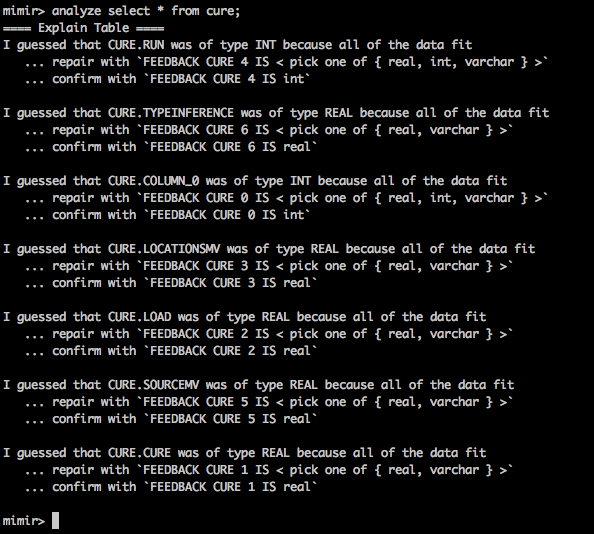
ANALYZE
Mimir keeps track of your wrangling to-dos, marking query results that might have errors. When you need to be more precise, the ANALYZE command zeroes in on the specific wrangling you need right now.
Unlike most other SQL-based systems, Mimir lets you make decisions during and after data exploration. All of Mimir's functionality is based on three ideas: (1) Mimir provides sensible best guess defaults, and (2) Mimir warns you when one of its guesses is going to affect what it's telling you, and (3) Mimir lets you easily inspect what it's doing to your data with ANALYZE.
Better still, you don't need any new infrastructure. Mimir attaches to ordinary relational databases through JDBC (We currently support SQLite, with SparkSQL and Oracle support in progress). If you don't care, Mimir just puts everything in a super portable SQLite database by default.
Documentation
If you want to use Mimir...
Get Mimir
5 minute overview
Mimir SQL
Mimir's Lenses
If you're having problems...
Issue Tracker
If you want to hack on Mimir...
Setting Up a Dev Environment
Conceptual Introduction to Mimir
Conceptual Introduction to the UI
ScalaDocs
Who Are We?
- The Team
- Mike Brachmann, Oliver Kennedy
- Research Advisors
- Oliver Kennedy, Boris Glavic
- Industry Advisors
- Ronny Fehling (Airbus), Dieter Gawlick (Oracle), Zhen Hua Liu (Oracle), Beda Hammerschmidt (Oracle)
- Alumni
- Aaron Huber, Poonam Kumari, William Spoth, Ting Xie, Gourab Mitra, Vinayak Karuppasamy, Arindam Nandi, Niccolò Meneghetti, Ying Yang, Sneha Krishnamurthy, Anand Sankar Bhagavandas, Shivang Aggarwal
Mimir is supported by gifts from Oracle, as well as grants from the NSF and Naval Postgraduate School
Presentations
Publications
- FastPDB: Towards Bag-Probabilistic Queries at Interactive Speeds
- Efficient Approximation of Certain and Possible Answers for Ranking and Window Queries over Uncertain Data
- The Right Tool for the Job: Data-Centric Workflows in Vizier
- Efficient Uncertainty Tracking for Complex Queries with Attribute-level Bounds
- Make Informed Decisions: Understanding Query Results from Incomplete Databases
- Uncertainty Annotated Databases - A Lightweight Approach for Approximating Certain Answers
- Learning From Query-Answers: A Scalable Approach to Belief Updating and Parameter Learning
-
Invited article extending a 'Best-of-SIGMOD' paper from SIGMOD 2017
- SchemaDrill: Interactive Semi-Structured Schema Design
- The Good and Bad Data
- Beta Probabilistic Databases: A Scalable Approach to Belief Updating and Parameter Learning
-
Invited to submit an extended version as a 'Best-of-SIGMOD' paper to ACM-TODS