Microkernel Notebooks
Oliver Kennedy
 Boris Glavic, Juliana Freire, Michael Brachmann, William Spoth, Poonam Kumari, Ying Yang, Su Feng, Heiko Mueller, Aaron Huber, Nachiket Deo, and many more...
Boris Glavic, Juliana Freire, Michael Brachmann, William Spoth, Poonam Kumari, Ying Yang, Su Feng, Heiko Mueller, Aaron Huber, Nachiket Deo, and many more...
But first...
Databases?

Data Structures?


CSE 562; Database Systems
- A bit of operating systems
- A bit of hardware
- A bit of compilers
- A bit of distributed systems
Applied Computer Science

For example...
CREATE VIEW salesSinceLastMonth AS
SELECT l.*
FROM lineitem l, orders o
WHERE l.orderkey = o.orderkey
AND o.orderdate > DATE(NOW() - '1 Month')
SELECT partkey FROM salesSinceLastMonth
ORDER BY shipdate DESC LIMIT 10;
SELECT suppkey, COUNT(*)
FROM salesSinceLastMonth
GROUP BY suppkey;
SELECT DISTINCT partkey
FROM salesSinceLastMonth
def really_expensive_computation():
return [
expensive_computation(i)
for i in range(1, 1000000):
if expensive_test(i)
]
print(sorted(really_expensive_computation())[:10])
print(len(really_expensive_computation()))
print(set(really_expensive_computation()))
def really_expensive_computation():
return [
expensive_computation(i)
for i in range(1, 1000000):
if expensive_test(i)
]
view = really_expensive_computation()
print(sorted(view)[:10])
print(len(view))
print(set(view))
Opportunity: Views are queried frequently
Idea: Pre-compute and save the view’s contents!
Btw... this idea is the essence of CSE 250.
When the base data changes,
the view needs to be updated too!
def init():
view = query(database)
Our view starts off initialized
Idea: Recompute the view from scratch when data changes.
def update(changes):
database = database + changes
view = query(database) # includes changes

def update(changes):
view = delta(query, database, changes)
database = database + changes
| delta | (ideally) Small & fast query |
| + | (ideally) Fast "merge" operation |
Intuition

Get off my database's lawn, punk kids
Why Jupyter Sucks
Microkernel Notebooks
Oliver Kennedy
Boris Glavic, Juliana Freire, Michael Brachmann, William Spoth, Poonam Kumari, Ying Yang, Su Feng, Heiko Mueller, Aaron Huber, Nachiket Deo, and many more...

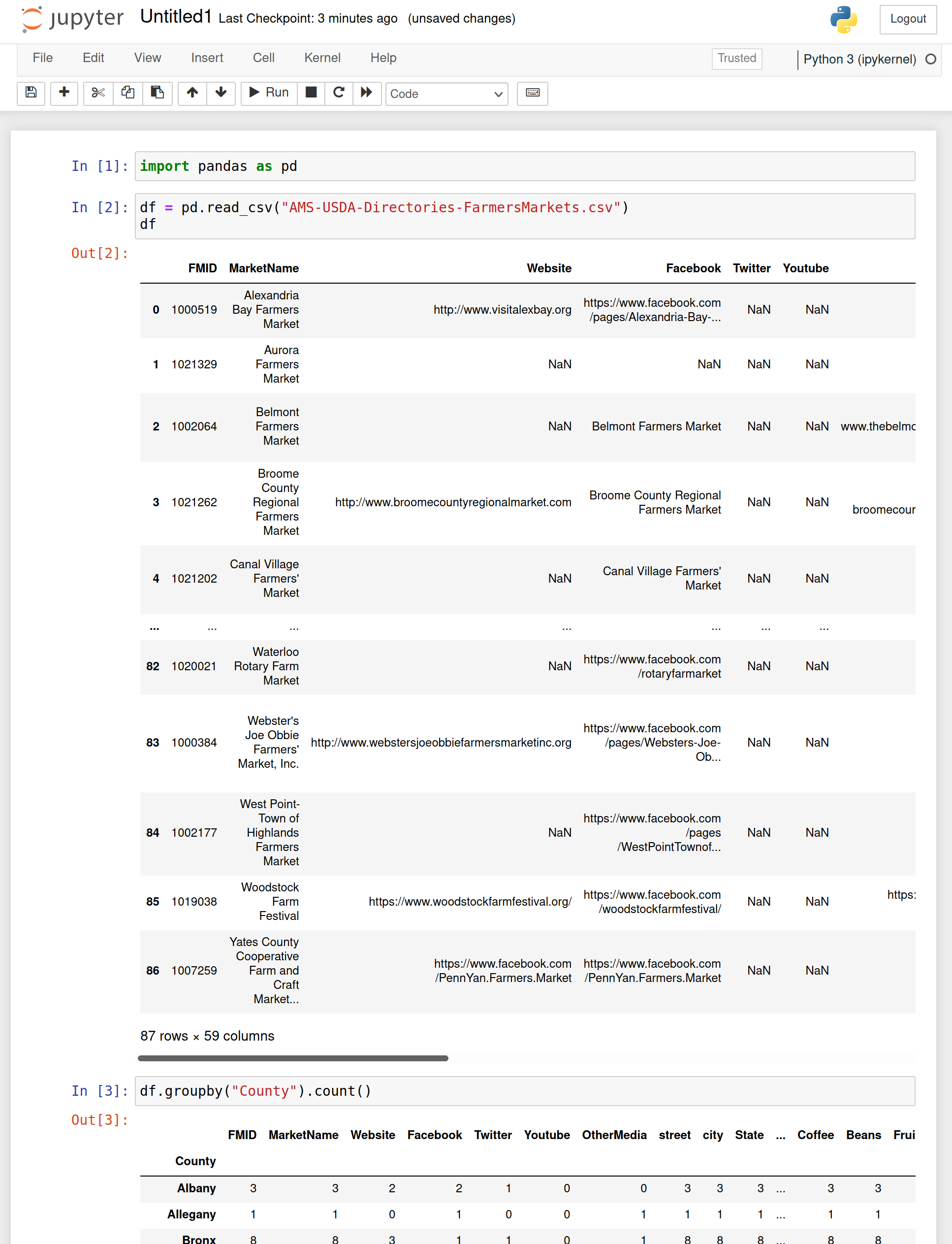
import pandas as pd
df = pd.read_csv("AMS-USDA-Directories-FarmersMarkets.csv")
df

df.groupby("County").count()
...


Cells are code snippets that get pasted into a long running kernel



Evaluation Order ≠ Notebook Order
... but why?
In a monokernel...
import pandas as pd
df = pd.read_csv("really_big_dataset.csv")
test = df.iloc[:800]
train = df.iloc[800:]
model = train_linear_regression(train, "target")
evaluate_linear_regresion(model, test, "target")
import pandas as pd
df = pd.read_csv("really_big_dataset.csv")
test = df.iloc[:500]
train = df.iloc[500:]
model = train_linear_regression(train, "target")
evaluate_linear_regresion(model, test, "target")
Q1: Which cells need to be re-evaluated?
Idea 1: All of them!
import pandas as pd
df = pd.read_csv("really_big_dataset.csv")
test = df.iloc[:500]
train = df.iloc[500:]
model = train_linear_regression(train, "target")
evaluate_linear_regresion(model, test, "target")
... but df is still around, and you can "re-use" it.
Idea 2: Skip cells that haven't changed.
... but you need to keep track of this.
Idea 3: Pull out your CSE 443 Textbooks
Data Flow Graph
Cell 3 changed, so re-evaluate only cells 4 and 5
... but
...
model = train_linear_regression(train, "target")
evaluate_linear_regresion(model, test, "target")
df = pd.read_csv("another_really_big_dataset.csv")
test = df.iloc[:500]
train = df.iloc[500:]
df has changed!
We want to "snapshot" df in between cells.
The kernel runs, snapshots its variables, and quits.
Microkernel Notebooks
- Lots of small "micro-kernels"
- Explicit inter-cell messaging
- Messsages are snapshotted for re-use
Demo