Intro
Feb 2, 2021
Garcia-Molina/Ullman/Widom: Ch. 1, 2.1-2.2

https://app.sli.do/event/iobhymgr
Why Are Databases Awesome?
They're Everywhere

$$$
| Rank | Organization | Sales (B$) | FY | Market cap (B$) | Headquarters | |
|---|---|---|---|---|---|---|
| 1 |  |
Microsoft | 118.2 | 2019 | 946.5 | Redmond, WA, US |
| 2 | |
Oracle | 39.6 | 2019 | 186.3 | Austin, TX, US |
| 3 |  |
SAP | 29.1 | 2019 | 134.9 | Walldorf, Germany |
| 4 | |
ADP | 14.5 | 2019 | 52.0 | New York City, NY, US |
| 5 | |
Adobe | 9.5 | 2019 | 132 | San Jose, CA, US |
| 6 | |
Salesforce | 13.3 | 2019 | 120.9 | San Francisco, CA, US |
| 7 | |
VMware | 9.0 | 2019 | 77.2 | Palo Alto, CA, US |
| 8 | |
Intuit | 6.4 | 2019 | 66.8 | Palo Alto, CA, US |
| 9 | |
SS&C Technologies | 6.3 | 2019 | 16.0 | Windsor, Connecticut |
| 10 | |
NetApp | 6.2 | 2019 | 11.0 | Sunnyvale, CA, US |
8 of 10 Forbes Top Software Companies
Have a Focus on Data Management Systems
Interesting Problems

What is "Databases"?
How do we ask and answer questions about data?
How do we manipulate and persist data?
Databases
| Techniques |
Data Modeling Cost-Based Optimization |
| Recipes |
Join Algorithms Index Data Structures |
| Knowledge |
The Memory Hierarchy Data Consistency |
Which Tools To Use
And When?
Template for 90% of this class
What is the best, correct technique for task X, when Y is true?
- How do you define Correct and Best?
- What correct alternatives are available?
- How do you find the best available alternative
General Course Information
Expectations
- Algorithms / Data Structures
- $O(\cdot)$ Analysis, Sort Algos, Trees, Hash Tables
- How to use a database
- CSE 4/560 (or equivalent)
- Scala
- Java, C++, C# or similar is usually good enough
- (but you need actual programming experience)
- (Rapid-start tutorial on Thursday)
Me
Oliver KennedyTA
Darshana BalakrishnanSyllabus/Course Info
https://odin.cse.buffalo.edu/teaching/cse-462/
https://odin.cse.buffalo.edu/teaching/cse-562/
(same link)
CMS (Forum, Assignments)
https://piazza.com/buffalo/spring2021/cse462562
Polls

|

|
| $150 | $50 |
| Index ToC |
No Index ToC Summary |
Course Structure
- Concepts (50% of Grade)
- Homework (20%; ~12 Assignments, Drop any 4); Groups of up to 4.
- TBD: Comprehensive Final 20%
- +10% to whichever you do better on
- Practicum (50% of Grade)
- Rebuild the guts of Spark's Catalyst Engine
- Solo Project
- 4 Checkpoints (+ 5 free points for Checkpoint 0)
Lectures
Lectures will be on YouTube, streaming T/R from 12:30-2 and available for later replay.
You don't need to attend, but you are paying me to be here.
I'll be monitoring the chat. Don't ever hesitate to ask a question or comment (No need to raise your hand first).
Please keep things civil and be respectful of your fellow classmates, TA, and anyone else around.

I've torn the guts out of Catalyst. What remains:
- SQL Parser
- Logical Plans: Relational Algebra Trees
- Expression: Primitive-valued expression trees + evaluation logic
Your mission: Replace the missing bits (sort of).
- Analysis: Tidying up SQL's corner cases
- Execution: Answering queries fast (single-node)
- Optimization: Eliminating redundancy
and picking the best algorithms.
We give you...
Gutted Catalyst
Data (CSV Files)
Schema Information (CREATE TABLE)
Questions (SQL Queries)
You give us...
Answers
(really really fast)
Real World Challenge
You get graded on your code's...
- Correctness
- ~1/3 credit for getting the right answer.
- Performance
- ~2/3 credit for getting it reasonably fast.
- +leaderboards for getting it really fast.
Checkpoint 0: "Hello World"
5/50 pts
- Submit a simple Scala program
- Make sure that the submission workflow works for you.
Checkpoint 1: "Get it Working"
10/50 pts
- Interpret Relational Algebra (Spark's LogicalPlan)
- Load CSV Files
- Run Basic Select, Project, Join Queries
- Nested Queries
Checkpoint 2: "Big Data"
12/50 pts
- Order By
- Limit
- Too much data for memory
Checkpoint 3: "Aggregates"
8/50 pts
- Aggregation
Checkpoint 4: "Precomputation"
15/50 pts
- You get a few minutes to pre-compute
- Load data
- Cache views
- Build indexes
Ways to Fail
- Start your project at the last minute
- Don’t go to office hours
- Don’t ask questions (on Piazza or in class)
- Wait until the deadline to submit for the first time
- Cheat

Academic Integrity
Cheating is submitting any work that you did not perform by yourself as if you did.
- References (when cited)
- Wikipedia, Wikibooks (or similar): OK
- Public Code
- Stack Exchange (or similar): Not OK
- Discussing concepts/ideas with classmates
- “A hash index has O(1) lookups”: OK (except during exams 😇 )
- Sharing code or answers with anyone
- “Just have a look at how I implemented it”: NOT OK
- For-hire code: NOT OK
MOSS
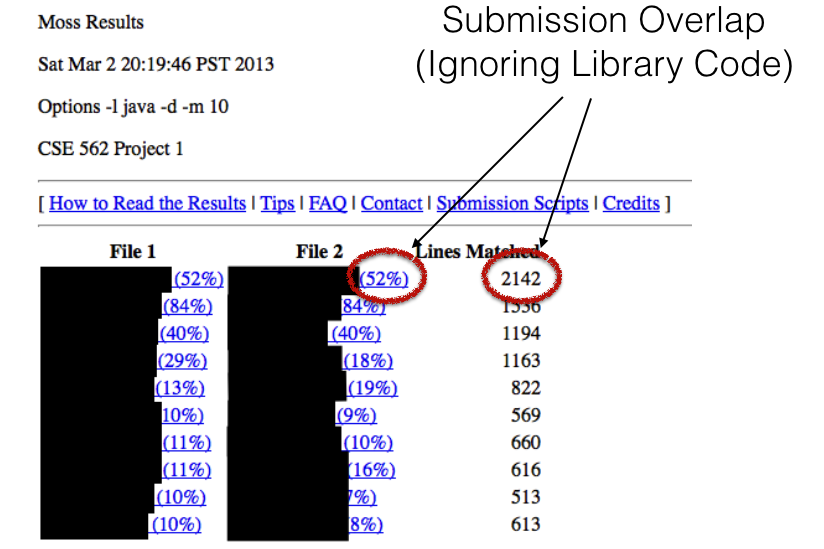
MOSS
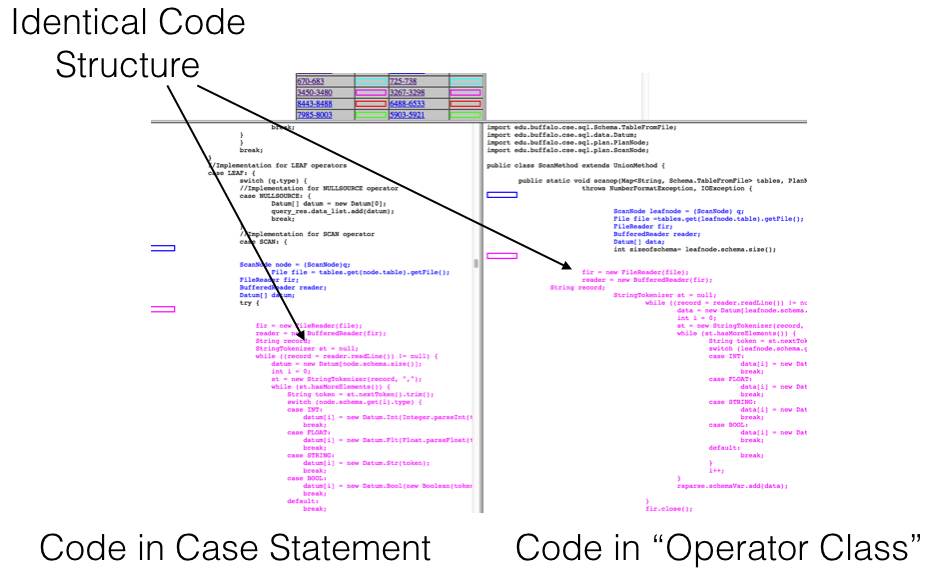
- Zero Tolerance
- If I catch you submitting someone else’s code (including pay-for-code services), you will fail the class.
- Group Responsibility
- If your teammate cheats on a group assignment, the entire group will be penalized.
- Share Code, Share Blame
- If someone else submits your code or other course materials as their own, you will be penalized as well.
Questions/Concerns?
What does a Data Management System Do?
- Analysis: Answering user-provided questions about data
- What kind of tools can we give end-users?
- Declarative Languages
- Organizational Datastructures (e.g., Indexes)
- Manipulation: Safely persisting and sharing data updates
- What kind of tools can we give end-users?
- Consistency Primitives
- Data Validation Primitives
So let's talk structure...
- Primitive
- Basic building blocks like Int, Float, Char, String
- Tuple
- Several ‘fields’ of different types. (N-Tuple = N fields)
- A Tuple has a ‘schema’ defining each field
- Set
- A collection of unique records, all of the same type
- Bag
- An unordered collection of records, all of the same type
- List
- An ordered collection of records, all of the same type
Your data is currently an Unordered Set
of Tuples with 100 attributes each.
Tomorrow, you’ll be repeatedly asked for 1 specific attribute
from 5 specific tuples identified by the first attribute
Can you do better?
https://app.sli.do/event/iobhymgr
Better Idea: Rewrite data into a 99-Tuple of Maps keyed on the 1st attribute
This representation is equivalent and better for your needs.
Declarative specifications make it easier to find equivalences.
Declarative Languages
- Don't need to think about algorithms.
- Independent of the data representation.
SQL
- Developed by IBM (for System R) in the 1970s.
- Standard used by many vendors.
- SQL-86 (original standard)
- SQL-89 (minor revisions; integrity constraints)
- SQL-92 (major revision; basis for modern SQL)
- SQL-99 (XML, window queries, generated default values)
- SQL 2003 (major revisions to XML support)
- SQL 2008 (minor extensions)
- SQL 2011 (minor extensions; temporal databases)
A Basic SQL Query
SELECT [DISTINCT] targetlist
FROM relationlist
WHERE condition
- Compute the $2^n$ combinations of tuples in all relations appearing in relationlist
- Discard tuples that fail the condition
- Delete attributes not in targetlist
- If DISTINCT is specified, eliminate duplicate rows
This is the least efficient strategy to compute a query! A good optimizer will find more efficient strategies to compute the same answer.
Example Data
SELECT * FROM Trees;Wildcards (*, tablename.*) are special targets that select all attributes.
| CREATED_AT | TREE_ID | BLOCK_ID | THE_GEOM | TREE_DBH | STUMP_DIAM | CURB_LOC | STATUS | HEALTH | SPC_LATIN | SPC_COMMON | STEWARD | GUARDS | SIDEWALK | USER_TYPE | PROBLEMS | ROOT_STONE | ROOT_GRATE | ROOT_OTHER | TRNK_WIRE | TRNK_LIGHT | TRNK_OTHER | BRNCH_LIGH | BRNCH_SHOE | BRNCH_OTHE | ADDRESS | ZIPCODE | ZIP_CITY | CB_NUM | BOROCODE | BORONAME | CNCLDIST | ST_ASSEM | ST_SENATE | NTA | NTA_NAME | BORO_CT | STATE | LATITUDE | LONGITUDE | X_SP | Y_SP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| '08/27/2015' | 180683 | 348711 | 'POINT (-73.84421521958048 40.723091773924274)' | 3 | 0 | 'OnCurb' | 'Alive' | 'Fair' | 'Acer rubrum' | 'red maple' | 'None' | 'None' | 'NoDamage' | 'TreesCount Staff' | 'None' | 'No' | 'No' | 'No' | 'No' | 'No' | 'No' | 'No' | 'No' | 'No' | '108-005 70 AVENUE' | '11375' | 'Forest Hills' | 406 | 4 | 'Queens' | 29 | 28 | 16 | 'QN17' | 'Forest Hills' | 4073900 | 'New York' | 40.72309177 | -73.84421522 | 1027431.14821 | 202756.768749 |
| '09/03/2015' | 200540 | 315986 | 'POINT (-73.81867945834878 40.79411066708779)' | 21 | 0 | 'OnCurb' | 'Alive' | 'Fair' | 'Quercus palustris' | 'pin oak' | 'None' | 'None' | 'Damage' | 'TreesCount Staff' | 'Stones' | 'Yes' | 'No' | 'No' | 'No' | 'No' | 'No' | 'No' | 'No' | 'No' | '147-074 7 AVENUE' | '11357' | 'Whitestone' | 407 | 4 | 'Queens' | 19 | 27 | 11 | 'QN49' | 'Whitestone' | 4097300 | 'New York' | 40.79411067 | -73.81867946 | 1034455.70109 | 228644.837379 |
| '09/05/2015' | 204026 | 218365 | 'POINT (-73.93660770459083 40.717580740099116)' | 3 | 0 | 'OnCurb' | 'Alive' | 'Good' | 'Gleditsia triacanthos var. inermis' | 'honeylocust' | '1or2' | 'None' | 'Damage' | 'Volunteer' | 'None' | 'No' | 'No' | 'No' | 'No' | 'No' | 'No' | 'No' | 'No' | 'No' | '390 MORGAN AVENUE' | '11211' | 'Brooklyn' | 301 | 3 | 'Brooklyn' | 34 | 50 | 18 | 'BK90' | 'East Williamsburg' | 3044900 | 'New York' | 40.71758074 | -73.9366077 | 1001822.83131 | 200716.891267 |
| '09/05/2015' | 204337 | 217969 | 'POINT (-73.93445615919741 40.713537494833226)' | 10 | 0 | 'OnCurb' | 'Alive' | 'Good' | 'Gleditsia triacanthos var. inermis' | 'honeylocust' | 'None' | 'None' | 'Damage' | 'Volunteer' | 'Stones' | 'Yes' | 'No' | 'No' | 'No' | 'No' | 'No' | 'No' | 'No' | 'No' | '1027 GRAND STREET' | '11211' | 'Brooklyn' | 301 | 3 | 'Brooklyn' | 34 | 53 | 18 | 'BK90' | 'East Williamsburg' | 3044900 | 'New York' | 40.71353749 | -73.93445616 | 1002420.35833 | 199244.253136 |
| '08/30/2015' | 189565 | 223043 | 'POINT (-73.97597938483258 40.66677775537875)' | 21 | 0 | 'OnCurb' | 'Alive' | 'Good' | 'Tilia americana' | 'American linden' | 'None' | 'None' | 'Damage' | 'Volunteer' | 'Stones' | 'Yes' | 'No' | 'No' | 'No' | 'No' | 'No' | 'No' | 'No' | 'No' | '603 6 STREET' | '11215' | 'Brooklyn' | 306 | 3 | 'Brooklyn' | 39 | 44 | 21 | 'BK37' | 'Park Slope-Gowanus' | 3016500 | 'New York' | 40.66677776 | -73.97597938 | 990913.775046 | 182202.425999 |
| ... and 683783 more | |||||||||||||||||||||||||||||||||||||||||
SELECT tree_id, spc_common, boroname
FROM Trees
WHERE boroname = 'Brooklyn'
In English, what does this query compute?
What is the ID, Commmon Name and Borough of Trees in Brooklyn?
| TREE_ID | SPC_COMMON | BORONAME |
|---|---|---|
| 204026 | 'honeylocust' | 'Brooklyn' |
| 204337 | 'honeylocust' | 'Brooklyn' |
| 189565 | 'American linden' | 'Brooklyn' |
| 192755 | 'London planetree' | 'Brooklyn' |
| 189465 | 'London planetree' | 'Brooklyn' |
| ... and 177287 more | ||
SELECT latitude, longitude
FROM Trees, SpeciesInfo
WHERE Trees.spc_common = SpeciesInfo.name
AND SpeciesInfo.has_unpleasant_smell = 'Yes';
In English, what does this query compute?
What are the coordinates of Trees with bad smells?
| LATITUDE | LONGITUDE | |||
|---|---|---|---|---|
| 40.59378755 | -73.9915968 | |||
| 40.69149917 | -73.97258754 | |||
| 40.74829709 | -73.98065645 | |||
| 40.68767857 | -73.96764605 | |||
| 40.739991 | -73.86526993 | |||
| ... and more | ||||
SELECT Trees.latitude, Trees.longitude
FROM Trees, SpeciesInfo
WHERE Trees.spc_common = SpeciesInfo.name
AND SpeciesInfo.has_unpleasant_smell = 'Yes';
... is the same as ...
SELECT T.latitude, T.longitude
FROM Trees T, SpeciesInfo S
WHERE T.spc_common = S.name
AND S.has_unpleasant_smell = 'Yes';
... is (usually) the same as ...
SELECT latitude, longitude
FROM Trees, SpeciesInfo
WHERE spc_common = name
AND has_unpleasant_smell = 'Yes';
Expressions
SELECT tree_id,
stump_diam / 2 AS stump_radius,
stump_area = 3.14 * stump_diam * stump_diam / 4
FROM Trees;
Arithmetic expressions can appear in targets or conditions. Use ‘=’ or ‘AS’ to assign names to these attributes. (The behavior of unnamed attributes is unspecified)
Expressions
SELECT tree_id, spc_common FROM Trees WHERE spc_common LIKE '%maple'
| TREE_ID | SPC_COMMON |
|---|---|
| 180683 | 'red maple' |
| 204325 | 'sycamore maple' |
| 205044 | 'Amur maple' |
| 184031 | 'red maple' |
| 208974 | 'red maple' |
SQL uses single quotes for ‘string literals’
LIKE is used for String Matches
‘%’ matches 0 or more characters
Union
SELECT tree_id FROM Trees WHERE spc_common = 'red maple'
UNION [ALL]
SELECT tree_id FROM Trees WHERE spc_common = 'sycamore maple'
Computes the set-union of any two union-compatible sets of tuples
Adding ALL preserves duplicates across the inputs (bag-union).
Aggregate Queries
SELECT [DISTINCT] targetlist
FROM relationlist
WHERE condition
GROUP BY groupinglist
HAVING groupcondition
The targetlist now contains (a) Grouped attributes, and (b) Aggregate expressions.
Targets of type (a) must be a subset of the grouping-list
(intuitively each answer tuple corresponds to a single group, and each group must have a single value for each attribute)
groupcondition is applied after aggregation and may contain aggregate expressions.
Aggregate Queries
SELECT spc_common, count(*) FROM Trees GROUP BY spc_common
| SPC_COMMON | COUNT |
|---|---|
| ''Schubert' chokecherry' | 4888 |
| 'American beech' | 273 |
| 'American elm' | 7975 |
| 'American hophornbeam' | 1081 |
| 'American hornbeam' | 1517 |
| ... and more | |
Next time...
Scala for Java programmers.