Mimir
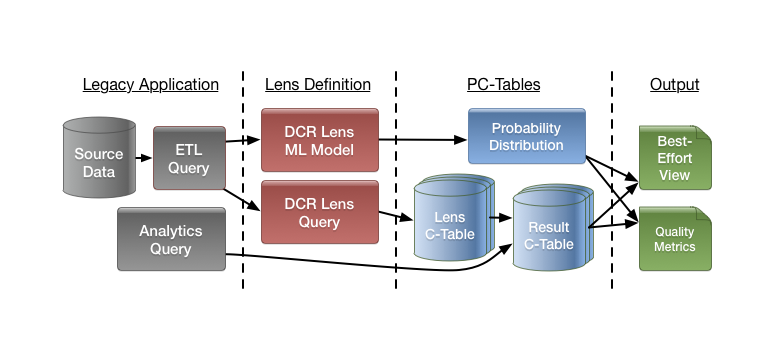
Historically, database management systems have assumed that source data is reliable. However obtaining reliable data is becoming an increasingly difficult proposition. Big data management systems operate at scales too large to reliably validate by hand. IoT data management systems operate in highly resource-constrained environments where obtaining reliable data in real-time may not be feasible.
As the adage goes: garbage-in, garbage-out. Classical data management systems allow unreliable data to be loaded and queried as if it were correct. From the perspective of a user or application posing queries over a dataset, there is no visible difference between reliable and unreliable query results.
Mimir changes all of that.
As a probabilistic database engine, Mimir makes uncertainty a first-class primitive through annotations on potentially invalid data. These annotations and their effect on the data are propagated through queries, helping users to understand not only why their results are unreliable, but also how much trust they can put into those results.
Using Mimir
By default, Mimir behaves as an ordinary relational database. In fact, it's possible to use Mimir as an ordinary database client without using any of its uncertainty management features (Mimir actually uses existing backend databases that do the bulk of the query processing and data management). Mimir's main capabilities are accessed through two new primitives called Lenses and EXPLAIN operations, both described below.
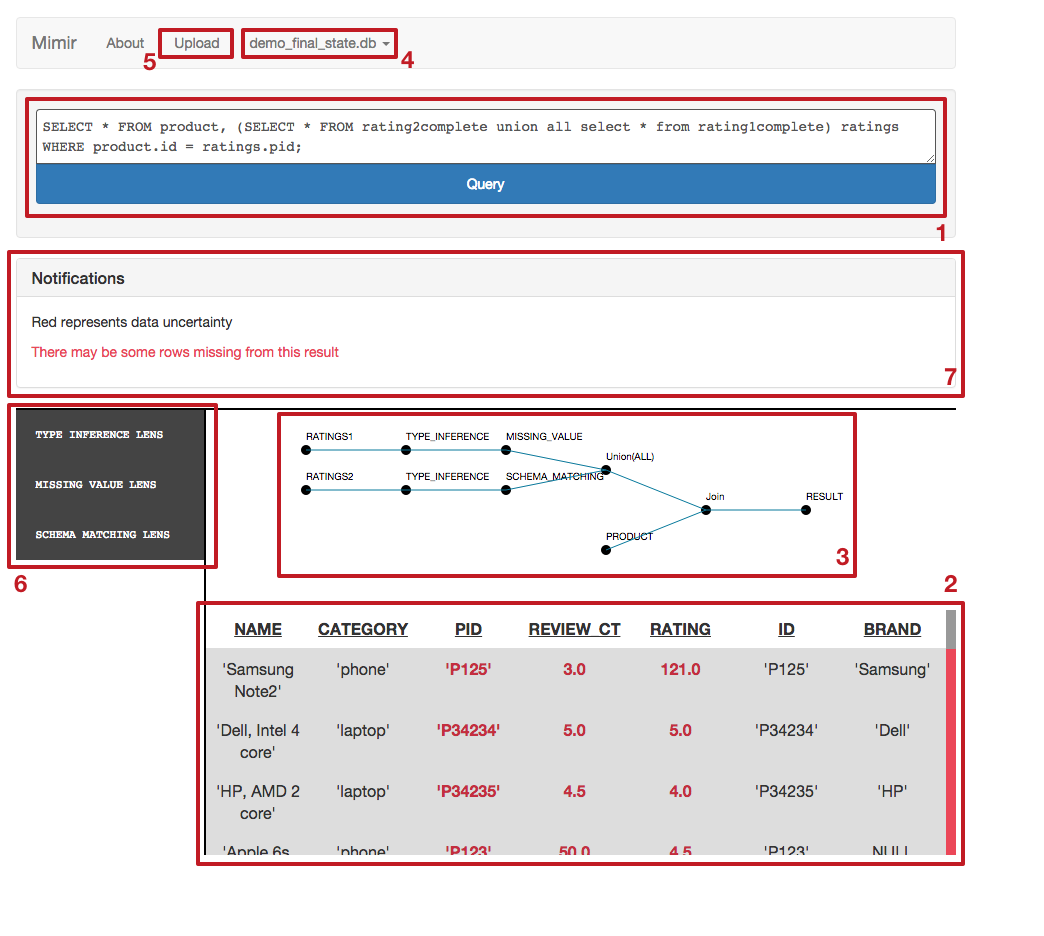
Mimir's User Interface
- The query field accepts SQL queries. Mimir accepts an extended form of SQL92, although support for aggregation is still in progress.
- Results are shown below. If you are que rying unreliable data, uncertain fields will be highlighted in red, and uncertain rows will be highlighted in grey and have a red bar to the right.
- A schematic view of the query lineage is shown alongside the results.
- Mimir can connect to databases through JDBC. The Database menu allows connections to other databases, and quick at-a-glance access to tables and views available in the current database.
- Mimir features a quick and easy CSV data loader.
- Lens construction wizards (see 'Lenses' below)
- The notification area shows contextual hints about the query.
Lenses
lens := CREATE LENS _name_
AS _query_
USING _model_
_model_ :=
| MISSING_VALUE(_col_ [, _col_ [, ...]])
| SCHEMA_MATCHING(_col_ _type_ [, _col_ _type_ [, ...]])
| TYPE_INFERENCE()
| ARCHIVAL(_period_)
| DOMAIN_CONSTRAINT(_col1_ _constraint_ [, _col_ _constraint_ [, ...]])
| XML_EXTRACT(_xmlschema_)
| MARKOV(.?.)
Lenses are a family of data processing components that model knowledge. A lens can be queried as a normal relational table or view; The contents of the lens depend on the specific type of lens _model_ being applied. Mimir presently includes lenses for three common ETL tasks, and we are rapidly developing new lenses. Each lens takes a SQL _query_ as input and applies a specific data transformation to the result. Examples of possible lenses include:
Schema Matching: The schema matching lens automatically remaps the columns of a relation to a new schema. Schema mappings are inferred based on the edit distances between the attributes of the source and target schemas.
Missing Value: The missing value lens replaces all
NULLvalues in a column. Replacement is done using a tree-based classifier trained on the remaining rows of the input table.Type Inference: The type inference lens automatically assigns types to each 'string' column in the input data. Types are guessed based on a majority vote over the best fit for all values in the column.
Archival: The archival lens
_period_ically runs and caches the result of the source query. The lens uses a combination of periodic sampling and bi-temporal query support in the underlying database to model the volatility of the source data and guess at the correct current value without needing to refresh the cache. (The Archival Lens is not complete)Domain Constraint: A more powerful version of the missing value lens. The domain constraint lens enforces type constraints on the data columns. Data not conforming to the constraint is replaced by a best-guess estimate based on the original value and the remaining attributes of the column. (The Domain Constraint Lens is not complete)
XML Extraction: A variant of the schema matching lens that uses example schemas to extract relational data from heterogeneous XML inputs. (The XML Extraction Lens is not complete)
Markov Process: Assuming the source data models transition events, produce a view of the data that represents the current state of the markov process at any given time.
The Mimir GUI further streamlines the process of lens creation through several lens creation 'wizards' (marker 6 in the diagram above). For most lenses, the only additional information required is a name for the lens.
The EXPLAIN Operation
Query results in Mimir are highlighted in red if the result is uncertain. That is, a result is highlighted if it is affected in any way by data being manipulated by a lens. For additional information, you may click on any uncertain row or cell to EXPLAIN it.
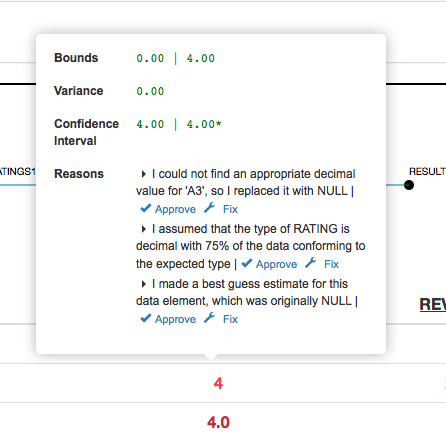
The EXPLAIN popup contains two areas: Quantitative statistics and qualitative explanations.
At the top are a set of quantitative statistics about the value's uncertainty. The precise set of statistics presented varies based on the value's type. Generally, they include at least one numerical measure of Mimir's confidence in the quality of the value such as variance or entropy, and one measure of the level of variation in the result values such as sample values or a confidence interval.
Below are qualitative explanations of why the value is uncertain. (what follows has not been implemented yet:) Explanations are ranked in terms of their contribution to the uncertainty of the value. Each explanation is associated with both an 'Accept' and a 'Fix' button. Clicking 'Accept' acknowledges the explanation. If no unacknowledged sources of uncertainty affect the result, its highlight color changes to green. Clicking 'Fix' brings up a Lens-specific dialog box that allows you to override how the Lens chose to repair the value in question.
Example Applications
Internet-of-Things
Consider the next-generation smart-house.
On-Demand ETL
Meet Alice. Alice is an analyst at HappyBuy, your friendly local electronics retailer. Alice is in charge of developing a big promotional offer. As an analyst, she starts by sifting through the data HappyBuy has available. She first wants to explore what products HappyBuy sells, so she finds and looks over the relevant table:
SELECT * FROM Product
| id | name | brand | category |
|---|---|---|---|
| P123 | Apple 6s, White | NULL |
phone |
| P124 | Apple 5s, Black | NULL |
phone |
| P125 | Samsung Note2 | Samsung | phone |
| P2345 | Sony to inches | NULL |
NULL |
| P34234 | Dell, Intel 4 core | Dell | laptop |
| P34235 | HP, AMD 2 core | HP | laptop |
Ugh! So much messy, missing data. Fortunately, Alice is using Mimir. She wraps the product data in a Missing Value lens.
CREATE LENS SaneProduct AS SELECT * FROM Product
USING MISSING_VALUE( 'category', 'brand' );
SELECT * FROM SaneProduct;
| id | name | brand | category |
|---|---|---|---|
| P123 | Apple 6s, White | Apple_*_ | phone |
| P124 | Apple 5s, Black | Black & Decker_*_ | phone |
| P125 | Samsung Note2 | Samsung | phone |
| P2345 | Sony to inches | Sony_*_ | laptop_*_ |
| P34234 | Dell, Intel 4 core | Dell | laptop |
| P34235 | HP, AMD 2 core | HP | laptop |
It's not perfect, but it's a start. Next, she turns to some product rating information that HappyBuy has collected over the years.
SELECT * FROM ratings1
| pid | rating | review_ct |
|---|---|---|
| P123 | 4.5 | 50 |
| P2345 | NULL |
245 |
| P124 | 4 | 100 |
SELECT * FROM ratings2
| pid | evaluation | num_ratings |
|---|---|---|
| P125 | 3 | 50 |
| P34234 | 5 | 245 |
| P34235 | 4.5 | 100 |
It looks like ratings is missing some data, and ratings2 has a mismatched schema. Alice creates a Missing Value lens for the former, and a Schema Matching lens for the latter.
CREATE LENS ratings1clean AS SELECT * FROM ratings1
USING MISSING_VALUE('rating');
CREATE LENS ratings2clean AS SELECT * FROM ratings2
USING SCHEMA_MATCH(pid string, rating float, review_ct int);
CREATE VIEW allratings AS
SELECT * FROM ratings1clean UNION ALL ratings2clean;
SELECT * FROM allratings;
| pid | rating | review_ct |
|---|---|---|
| P123 | 4.5 | 50 |
| P124 | 4 | 100 |
| P125_*_ | 3_*_ | 50_*_ |
| P2345 | 4_*_ | 245 |
| P34234_*_ | 5_*_ | 245_*_ |
| P34235_*_ | 4.5_*_ | 100_*_ |
Now she's getting somewhere. Alice combines this new information with what she had before.
SELECT name, rating, category FROM allratings r, products p WHERE p.id = r.pid;
| name | rating | category | notes |
|---|---|---|---|
| Apple 6s, White | 4.5 | phone | |
| Apple 5s, Black | 4 | phone | |
| Samsung Note2 | 3_*_ | phone | * |
| Sony to inches | 4_*_ | laptop_*_ | |
| Dell, Intel 4 core | 5_*_ | laptop | * |
| HP, AMD 2 core | 4.5_*_ | laptop | * |
Alice decides to explore moderately rated laptops:
SELECT name FROM allratings r, products p
WHERE p.id = r.pid AND p.category = 'laptop'
AND r.rating <= 4.5 AND r.rating >= 4.0
| name | notes |
|---|---|
| Sony to inches | * |
| HP, AMD 2 core | * |
Technology